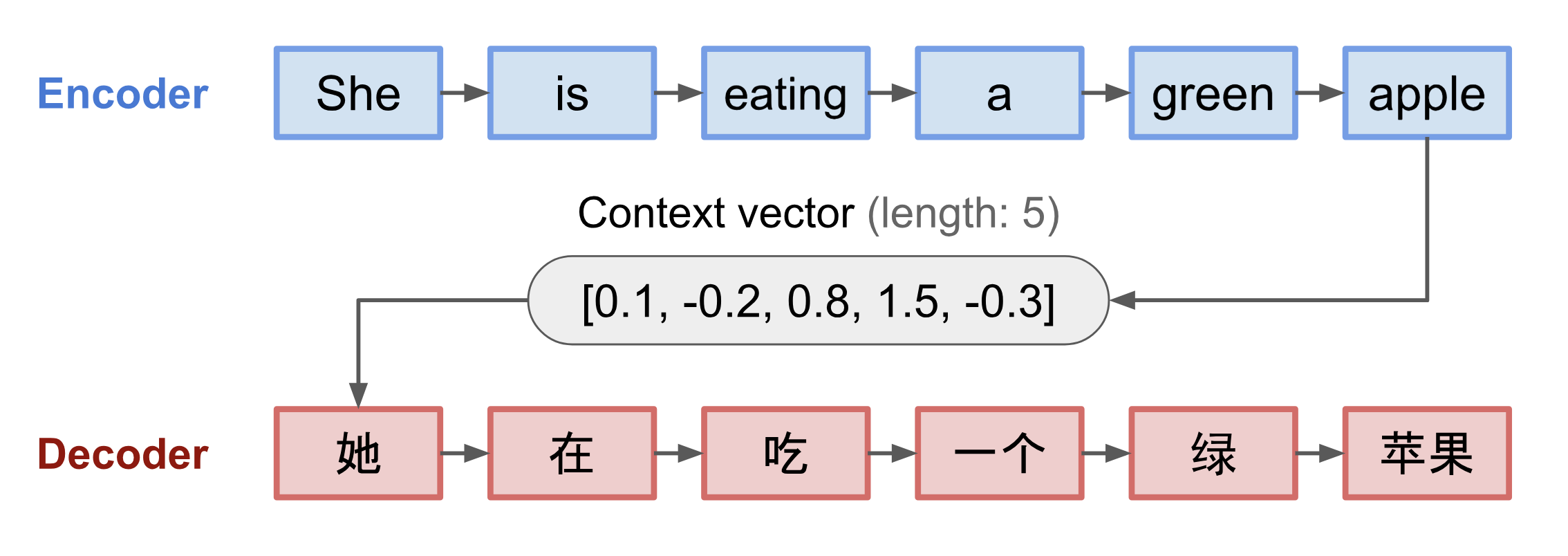
Attention is a technique for attending to different parts of an input vector to capture long-term dependencies. Within the context of NLP, traditional sequence-to-sequence models compressed the input sequence to a fixed-length context vector, which hindered their ability to remember long inputs such as sentences. In contrast, attention creates shortcuts between the context vector and the entire source input. Below you will find a continuously updating list of attention based building blocks used in deep learning.
Attention is, to some extent, motivated by how we pay visual attention to different regions of an image or correlate words in one sentence. Take the picture of a Shiba Inu in Fig. 1 as an example.
A Shiba Inu in a men’s outfit. The credit of the original photo goes to Instagram @mensweardog.
Human visual attention allows us to focus on a certain region with “high resolution” (i.e. look at the pointy ear in the yellow box) while perceiving the surrounding image in “low resolution” (i.e. now how about the snowy background and the outfit?), and then adjust the focal point or do the inference accordingly. Given a small patch of an image, pixels in the rest provide clues what should be displayed there. We expect to see a pointy ear in the yellow box because we have seen a dog’s nose, another pointy ear on the right, and Shiba’s mystery eyes (stuff in the red boxes). However, the sweater and blanket at the bottom would not be as helpful as those doggy features.
Similarly, we can explain the relationship between words in one sentence or close context. When we see “eating”, we expect to encounter a food word very soon. The color term describes the food, but probably not so much with “eating” directly.
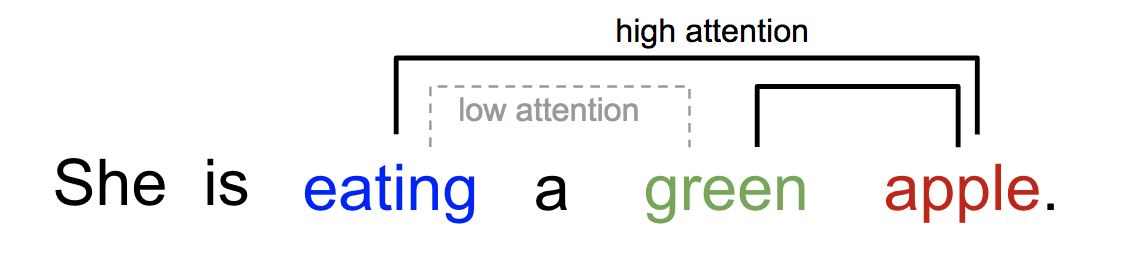
One word "attends" to other words in the same sentence differently.
In a nutshell, attention in deep learning can be broadly interpreted as a vector of importance weights: in order to predict or infer one element, such as a pixel in an image or a word in a sentence, we estimate using the attention vector how strongly it is correlated with (or “attends to” as you may have read in many papers) other elements and take the sum of their values weighted by the attention vector as the approximation of the target.
Broadly speaking, it aims to transform an input sequence (source) to a new one (target) and both sequences can be of arbitrary lengths. Examples of transformation tasks include machine translation between multiple languages in either text or audio, question-answer dialog generation, or even parsing sentences into grammar trees.
The seq2seq model normally has an encoder-decoder architecture, composed of:
Both the encoder and decoder are recurrent neural networks, i.e. using LSTM or GRU units.